





Le traitement du langage naturel n’est pas un nouveau venu dans l’arène technologique. Mais avec les progrès réalisés ces dernières années, cette banche de l’intelligence artificielle a pris une nouvelle dimension, jusqu’à s’incorporer à de nombreux programmes informatiques de la vie de tous les jours (à l’image des traducteurs automatiques).
Google s’est saisi de cette technologie en introduisant le langage naturel dans son algorithme de classement et, plus récemment, en proposant aux entreprises une API dédiée, Google NLP. Partons à la découverte des liens entre Google et le NLP (Natural Language Processing) et voyons comment cette technologie influe sur l’indexation et le positionnement des pages web, et par conséquent sur les stratégies de référencement naturel.
Qu’est-ce que le traitement automatique du langage naturel ?
Avant d’entrer dans le détail du travail de Google sur le NLP, il faut comprendre en quoi consiste ce Natural Language Processing (traitement automatique du langage naturel). Ce sous-domaine de l’intelligence artificielle a vocation à donner la faculté à un programme informatique de comprendre et d’interpréter le langage tel qu’il est parlé et écrit par les êtres humains, dans toutes ses complexités et ses nuances. Ainsi, un algorithme qui utilise le NLP est capable d’analyser les phrases, de saisir le sens des mots dans leur contexte, et in fine de générer lui-même du langage pour communiquer.
Le traitement automatique du langage naturel mêle des compétences informatiques, mathématiques et linguistiques. Dans le domaine de l’intelligence artificielle, il se place au croisement du machine learning et du deep learning (deux méthodes d’apprentissage autonome), comme on peut le voir sur le schéma ci-dessous :

(Source : Sidartha Mehra, researchgate.net)
Le but est de fluidifier les « communications » entre les Hommes et les machines, en aidant ces dernières à parler le même langage que les premiers. Avec deux effets immédiats et tangibles : la simplification de l’utilisation des technologies, et l’automatisation rapide des tâches rébarbatives grâce à la capacité des programmes à traiter d’énormes volumes de données brutes en un temps record. Ces informations, une fois structurées, peuvent ensuite être exploitées.
Dans les faits, le traitement automatique du langage naturel est déjà employé pour des applications utilisées au quotidien par les particuliers et les entreprises (sans même parler encore des moteurs de recherche et de l’API Google NLP). Quelques exemples concrets :
- Les traducteurs automatiques, comme Google Translate, qui restituent un texte dans la langue souhaitée de manière instantanée.
- Les assistants vocaux, ces logiciels intégrés aux smartphones ou aux ordinateurs (Siri, Cortana) et aux enceintes connectées (Google Home, Alexa).
- Les chatbots, des programmes qui simulent des conversations humaines et qui sont capables de répondre aux questions simples des utilisateurs (ils pullulent sur les sites web des entreprises).
- Les correcteurs automatiques, comme celui qui est intégré à Microsoft Word, ou le logiciel Antidote.
Eh oui : si vous avez déjà utilisé un traducteur instantané ou cliqué sur le correcteur de votre document Word, vous avez employé un outil qui fait appel à des technologies de machine learning et qui s’attache à comprendre le langage naturel. D’autres applications, plus spécifiques et souvent employées par les professionnels, existent également : transcription automatique de langage parlé en texte (et inversement), résumé automatique avec reformulation et paraphrase, analyse de la teneur émotionnelle d’un contenu, modélisation de langage naturel sous forme de phrases complètes, outil d’analyse de contenus textuels (comme Google NLP), etc.
De façon plus générale, tous les programmes qui s’appuient sur la compréhension du langage naturel reposent sur une technologie NLP, et tous ont pour but de simplifier les tâches humaines. On est donc très loin des fantasmes parfois associés aux progrès de l’intelligence artificielle, avec ses machines qui prennent le pouvoir !
L’histoire du traitement du langage naturel
Le travail de Google sur le NLP n’est qu’une nouvelle avancée dans un domaine déjà ancien, dont la naissance coïncide presque avec celle des ordinateurs. Les premières expériences de traitement automatique du langage naturel datent en effet des années 1950 avec la mise au point d’outils de traduction instantanée, dans un contexte politique (celui de la Guerre froide) aux enjeux favorables à ce type de recherche. La notion de « programme conversationnel » est alors au cœur des travaux de plusieurs scientifiques : c’est l’époque du fameux test exposé par Alan Turing dans son article « Computing machinery and intelligence » (source).
Le premier robot conversationnel de l’histoire, ELIZA, est créé par Joseph Weizenbaum dans un laboratoire nord-américain entre 1964 et 1966. Plus tard, dans les années 1980, après une succession de programmes capables de structurer l’information en données compréhensibles par les ordinateurs, l’augmentation des capacités de traitement ouvre la voie à des usages inédits pour le NLP. Cela, notamment via l’introduction des algorithmes de machine learning : les ordinateurs deviennent aptes à « apprendre » et à définir leurs propres règles.
Depuis le début du XXIe siècle, tous les feux (technologiques) sont au vert pour favoriser le développement du traitement automatique du langage naturel : approfondissement du deep learning, augmentation exponentielle de la puissance de calcul des ordinateurs, explosion du volume des données… Avec, à la clé, des applications concrètes, accessibles à l’utilisateur lambda, comme l’apparition du premier assistant virtuel installé sur un smartphone fin 2011 sur l’iPhone 4S, puis celle des enceintes connectées (Amazon en 2014, Google en 2016).
Comment fonctionne le Natural Language Processing ?
L’idée qui sous-tend la compréhension du langage naturel n’est donc pas neuve, mais elle a fait des progrès rapides avec le deep learning. Cette méthodologie s’appuie sur l’utilisation de réseaux neuronaux artificiels qui « imitent » le cerveau humain. Car le langage « naturel » a ceci de complexe qu’il accueille de nombreuses subtilités, difficiles à appréhender par les machines : les sous-entendus, l’humour, les métaphores, les antiphrases… Les technologies de NLP ambitionnent donc de saisir ces nuances et de réussir à les associer à un apprentissage autonome, dans le but de convertir le langage en données brutes, de générer des interactions avec les utilisateurs, et de créer des conversations intelligentes.
Dans ce but, l’algorithme utilise des récurrences, des schémas et des corrélations pour décomposer le langage humain, puis pour en dégager du sens. Les éléments constitutifs du discours sont catégorisés et segmentés, les mots et les groupes de mots sont séparés et se voient attribuer des fonctions selon leur morphologie. De sorte que le programme est capable de distinguer un groupe nominal, un verbe conjugué, différentes propositions, des compléments, une personne, un genre, un nombre, etc. Plusieurs méthodologies entrent en ligne de compte (l’analyse de la fréquence des termes, la comparaison des occurrences d’un mot-clé à proportion dans plusieurs textes d’un même corpus, l’étude du contexte…), ainsi que de multiples niveaux de traitement du langage :
- analyse lexicale,
- analyse syntaxique,
- analyse sémantique,
- analyse pragmatique.
C’est exactement le fonctionnement qu’on retrouve dans les applications que fait Google du NLP, à l’instar de son algorithme BERT.
Google et le NLP : le traitement du langage naturel intégré à l’algorithme du moteur de recherche
En matière de traitement automatique du langage naturel, Google est une référence, mais nous allons nous intéresser en priorité à la façon dont cette technologie est employée pour transformer les processus d’indexation et de positionnement des pages web.
Pour comprendre comment évolue l’algorithme de Google, il faut toujours regarder du côté de l’expérience utilisateur. La firme de Mountain View veut en effet garantir la satisfaction des internautes qui emploient son moteur de recherche en leur proposant des résultats aussi pertinents que possible, ce qui suppose d’améliorer en continu la qualité des pages mises en avant dans sa SERP.
Dans ce contexte, la compréhension des requêtes formulées par les utilisateurs est un enjeu majeur. Il ne s’agit plus seulement de saisir globalement le sens des mots, mais d’identifier l’intention qui se cache derrière la recherche afin de mieux y répondre. Pour cela, il faut saisir les nuances d’une requête, mais aussi détecter les termes qui expriment un « sentiment ».
Ce travail de Google sur le NLP a donné lieu au lancement, en 2019, de l’algorithme BERT – la mise à jour la plus importante en cinq ans pour la firme (selon ses propres termes) et un véritable bond en avant dans le fonctionnement des moteurs de recherche. Car BERT ne se contente plus de traiter les requêtes mot à mot : il tisse des liens entre les termes employés afin de prendre en compte le contexte de la recherche et d’en saisir le « sens profond ». Dans cette optique, il s’intéresse à tous les termes utilisés, y compris les mots de liaison et les prépositions, et évalue le « sentiment » qui ressort de la requête en lui attribuant un score (positif, négatif ou neutre).

Au moment de son lancement, l’algorithme BERT (pour Bidirectional Encoder Representations from Transformers) est l’aboutissement technologique des recherches de Google en NLP. Il s’appuie sur deux piliers :
- les données (modèles préformés : des ensembles d’informations à analyser via le traitement automatique du langage naturel) ;
- et la méthodologie (la manière dont l’algorithme utilise ces modèles).
Autrement dit, avec BERT, Google entend « lire » dans les pensées des utilisateurs en comprenant non pas seulement la requête, mais ce qu’elle ne dit pas explicitement. C’est aussi un levier pour appréhender les requêtes inédites, celles qui sont formulées pour la première fois, et que Google évalue (à l’époque) à environ 15 % des recherches quotidiennes.
En 2021, le travail de Google sur le NLP s’est intensifié pour donner MUM (Multitask Unified Model), une mise à jour de son algorithme qui améliore encore la compréhension du langage naturel et, ce faisant, la pertinence des réponses apportées aux internautes. En particulier, MUM se focalise sur ce que Google appelle les « requêtes complexes », caractérisées par leur longueur et par l’inclusion de plusieurs propositions. Le but de MUM est de pouvoir répondre à ces requêtes en une seule fois en s’appuyant sur des fonctionnalités avancées : extraction d’informations issues de plusieurs formats de contenus, affichage de ressources extraites de résultats dans 75 langues (avec traduction instantanée) et prise en charge de multiples tâches en simultané.
Le traitement automatique du langage naturel chez Google, ça change quoi concrètement pour le SEO ?
Ce qu’il faut comprendre, que c’est que l’intégration au moteur de recherche de Google du NLP a pour objectif d’améliorer les services fournis aux internautes. Les technologies de traitement du langage naturel aident les algorithmes à mieux comprendre les requêtes des utilisateurs et à leur apporter des réponses plus pertinentes, susceptibles de les satisfaire.
C’est d’autant plus important pour Google que ces besoins sont dictés par l’évolution des comportements, en particulier par l’utilisation grandissante de la recherche vocale – elle-même permise par les applications du NLP. Une large enquête menée en 2019 par Uberall (et relayée ici) montre que 21 % des personnes interrogées utilisent la recherche vocale chaque semaine. Or les requêtes formulées à l’oral font appel au langage naturel et s’avèrent donc bien plus complexes à comprendre pour les moteurs que des requêtes génériques composées de quelques mots-clés.
Conséquemment, à mesure que le travail de Google sur le NLP s’intensifie et que l’algorithme intègre toujours plus de critères liés au langage naturel, il devient indispensable pour les webmasters d’optimiser leurs pages en tenant compte de ces changements. Depuis le lancement de BERT, les experts du référencement naturel ne sont pas avares en recommandations pour adapter les contenus à cette nouvelle donne :
- écrire pour les utilisateurs plutôt que pour les robots crawlers,
- apprendre à mieux connaître son audience pour répondre avec plus de pertinence à ses attentes,
- simplifier le langage et employer un ton plus conversationnel,
- travailler le champ sémantique de la page pour consolider le contexte et aider l’algorithme à comprendre les enjeux du sujet traité.
Plus récemment, Google a lancé un outil spécifique intégrant le langage naturel qui aide les utilisateurs à extraire des insights de textes non structurés. Cet outil, sobrement appelé Google NLP, est une API qui permet d’examiner un contenu textuel et d’en tirer des données à exploiter dans le cadre d’une stratégie SEO. Google NLP vous donne une idée de la façon dont l’algorithme appréhende un texte et de ce qu’il comprend en analysant ses mots-clés, sa sémantique, sa syntaxe, son sentiment général et ses « entités » (mots ou phrases qui représentent des objets pouvant être identifiés et classés). Voici un exemple des résultats donnés par l’outil :
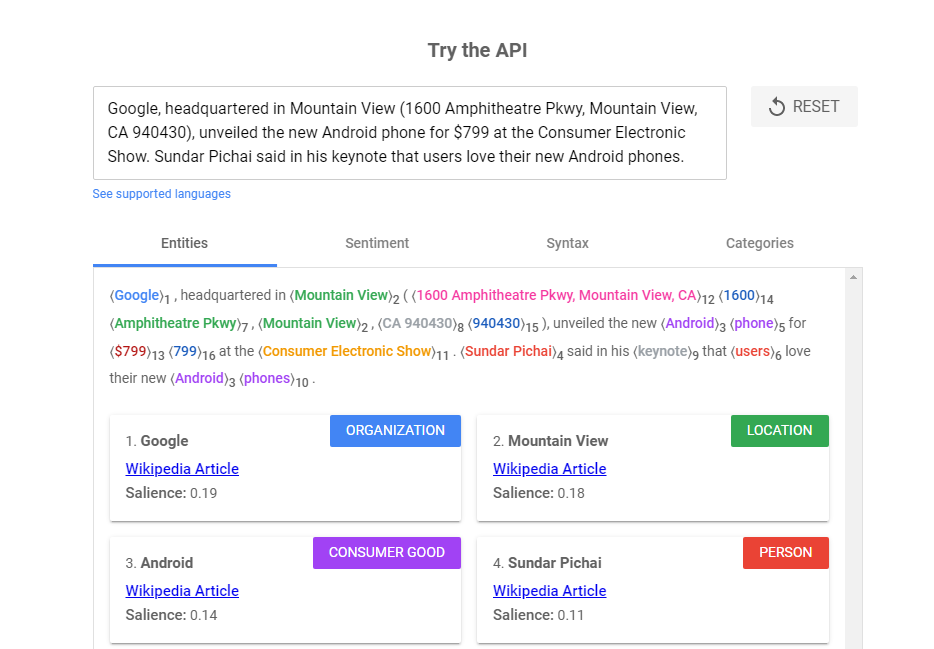
Le principe est simple : Google NLP permet de comparer le résultat de l’analyse aux pages qui arrivent en tête de la SERP, puis d’appliquer les mêmes recettes lors de l’optimisation, par exemple en ciblant une certaine combinaison de mots-clés qui témoignent d’une intention particulière de la part des internautes. Toutes choses étant égales (en termes de critères SEO), il est théoriquement possible de bénéficier pour son contenu d’un classement proche des pages les mieux positionnées par Google, dès lors qu’il répond aux attentes du moteur sur le plan du langage naturel.
Autre point essentiel à prendre en compte : les liens, à la fois internes et externes. Ceux-ci prennent une nouvelle dimension à l’aune du travail de Google sur le NLP : plus que jamais, l’optimisation SEO doit tenir compte du contexte de la page en ce qui concerne le placement des liens et la pertinence des ancres. Les liens doivent avoir pour but d’améliorer l’expérience utilisateur et rien d’autre – ce qui, par ailleurs, n’enlève rien à leur poids SEO.
En somme, mieux l’on saisit le fonctionnement de Google et du NLP, et plus il est possible de comprendre ce que l’algorithme attend des pages web les plus pertinentes : celles qu’il va choisir de mettre en avant pour les utilisateurs. Cela ne remet nullement en cause l’importance des facteurs de classement traditionnels, mais tend à accentuer la place donnée à la pertinence et la qualité des contenus, à l’expérience utilisateur, et à l’optimisation des différents formats de contenus (textes, images, vidéos et fichiers audio). Il est donc plus que temps de se mettre à l’heure du langage naturel !



